Note: The below poll serves only to gauge general sentiment towards the change and is not a binding vote, following the process outlined in PIP-8.
- Yes
- No
PIP-9: Performance Benchmark Adjustment
Authors:
Delroy Bosco
Jackson Lewis
Harry Rook
Mateusz Rzeszowski
Status : Final
Type: Contracts
Abstract
Following on from the favorable signal received for PIP-4, the validator performance metrics were implemented and released as an additional feature to the Polygon Staking Dashboard to better inform delegators about validator health.
The following PIP proposes to maintain the current level of Performance Benchmark at 95%, instead of changing it to 98% at checkpoint number 42,943, as defined in the initially-proposed timeline (in PIP-4).
Motivation
If Performance Benchmark 2 (“PB2”) were to be introduced today, 18 validators would underperform PB2, falling into grace periods.
The potential for 18 subsequent offboardings presents a concern as it takes time for 18 new validators to onboard and sync their nodes. This could be detrimental to network performance and overall developer and user experience.
Rationale
PIP-4 specified two performance benchmarks:
PB1 → 95% of median average of last 700 checkpoints signed by validator set (first 2,800 checkpoints)
PB2 → 98% of median average of last checkpoints signed by validator set (continues thereafter)
This implementation method was chosen to ease validators into the process and improve their uptime over time. Pushing validators to achieve an unattainable uptime would have led to a large number of Final Notices and resultant offboardings.
Since the launch of the performance metrics it can be observed that:
- Overall validator performance (in terms of checkpoint signing) has improved:
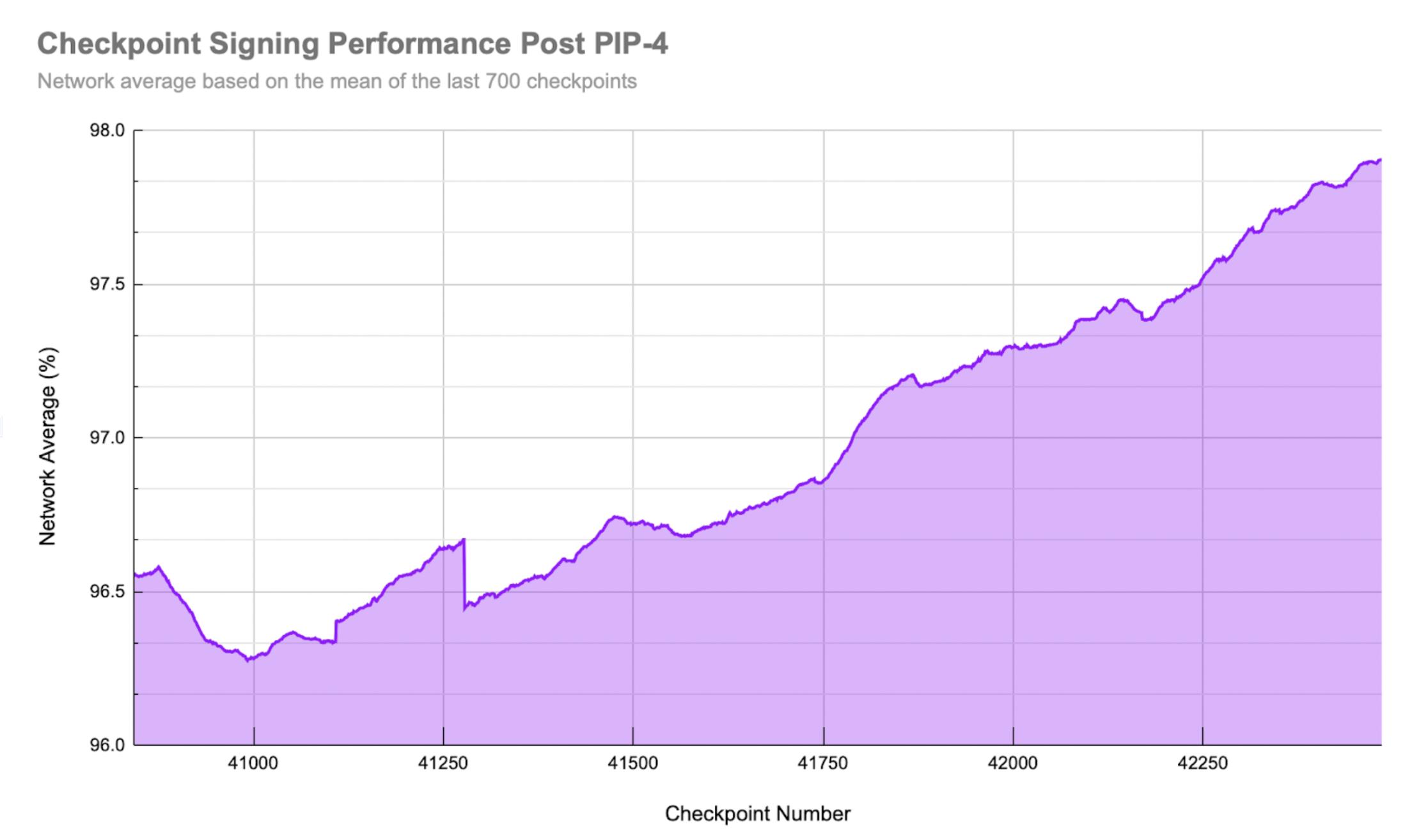
Currently it can be observed that:
- 5 validators are operating below the current Performance Benchmark 1 (“PB1”),
- 18 validators are operating below the maximum Performance Benchmark (median average of 100 * 98%) possible under PB2; and,
- 2 validators have received Final Notices so far.
It can be seen that the current performance benchmark has provided upward pressure on validator performance. Whilst also providing a steady amount of churn in the validator set, effectively identifying and removing underperforming validators, allowing for the onboarding of new ones. Over time, this process should strengthen the set as a whole.
Based on the above, we propose to keep the Performance Benchmark at its current level until the network shows it is capable of performing at a higher threshold.
Specification
In order to maintain a balanced performance benchmark, we propose the following:
Maintain the current level of required performance:
- PB → 95% of median average of last 700 checkpoints signed by the validator set
Security Considerations
If the performance benchmark is set too high, it may result in too many validator offboardings which could temporarily impact network security whilst new validators are being onboarded.
Based on the current state of network performance, 2 validators have received final notices since the performance data set began at checkpoint 40,143.
Conversely, if the Performance Benchmark is set at too low of a level, it may not provide sufficient upward pressure on checkpoint signing performance; which is one of the network’s key security features. In the long term, this would reduce the efficacy of the framework.
Conclusion
When validators have adapted to the higher level of performance necessary to maintain a validator slot (expressed by an overall increase in the total % of checkpoints signed by the network), the Performance Benchmark may gradually be amended to a level agreed upon by the community.
Notes
- The context provided about validator performance was taken at checkpoint number 42,512.
Copyright
All copyrights and related rights in this work are waived under CC0 1.0 Universal.